Predicting the next music stars with machine learning
On 23 and 24 November 2018, a coding hackathon was organized in the headquarter of IBM Brussels. Each team has to solve a real life problem of an IBM client by making use of IBM Cloud services. IT-professors of Belgian universities were invited to send teams of four students with programming experience to compete in this hackathon. In total, 5 universities took up the challenge. This post briefly explains the solution we came with to our challenge, and which led us to the third place of this hackathon.

Sabam, one of the Belgian associations of authors, composers, and publishers, is always on the lookout for emerging talent. Emerging bands are not always aware of their rights and the money they can rightfully earn for public performances. As part of Sabam’s mission, they want to reach out to these bands and inform them about authors’ rights, their rights, the ins and outs of publishing deals, and the general “what’s in it for you”. Authors that are still under the radar of the mainstream press but are about to boom are their primary target.
Our mission was to predict what Belgian, French, or Dutch musical authors/bands are booming under the radar, what the chatter is about, where the buzz is.
The problem
Every day, the account manager of Sabam looks for new talents to recruit in Belgium, France, and the Netherlands. To do so, he uses several online platforms like Spotify, YouTube, or Facebook, to spot them.
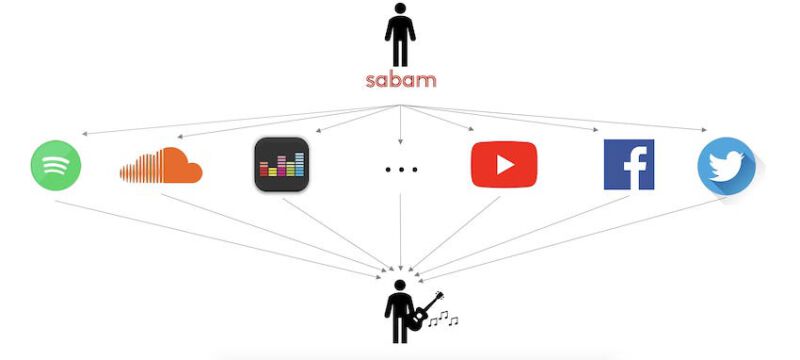
The problem is that this task is quite time-consuming, and it is not a funny thing to do. Moreover, when we talk about a new artist on social media, it’s often already too late, he has probably been contacted by another company.
So concretely, what does Sabam wants? It wants to detect new potential talents before anyone else does.
Our solution
Our solution consists of using some machine learning algorithms that would look, on the same platforms that the Sabam employee daily uses, for some signs about new songs that could be a buzz. Given a new release, if we can predict that it will be a hit, then the emerging artist is probably someone that Sabam wants to recruit.
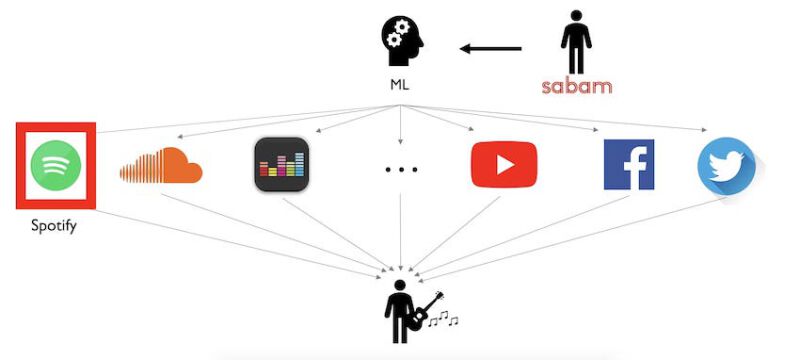
For a question of time during this hackathon, we decided to focus on Spotify. Why Spotify? Because it has a great Web API that allows us to get extremely precise data about a song such as its tempo, energy, accousticness, or danceability. Concretely, our idea with Spotify was to analyze these features for a considerable amount of songs of all genres and find a correlation between a song’s characteristics and its popularity.
How do we define the popularity of a song? Well, the Spotify Web API also provides a “popularity” feature for all its songs, giving a value between 0 and 100 (100 being the maximal level of popularity of a song). This feature is a function of the number of views of the song on Spotify, but it also decreases over time such that a buzz from two years ago has a lower popularity value than a buzz from last week.
First step — Collecting data
For our machine learning algorithm to train at best, we wanted many tracks of all possible genres.
Does the language matter? Well, even if Sabam only looks for new talents from Benelux and France, where most of the songs are sung in French and Dutch, having other languages will not skew our model. Indeed, if you like Spanish music, it’s probably for its tempo or its danceability more than for its lyrics. And so, if a comparable beat appears in a French song, the chances are that you will also probably like it.
Then, does the year of release matter? Of course it does! Sabam wants to know what is going to buzz now, depending on the current hype. The problem is that the Spotify API doesn’t allow you to select all the songs from a specific year. But given that the popularity feature decreases over time, it’s not a big deal if we consider older songs in our dataset because even if they have been a hit in the past, their popularity value will be lower than the one of a current hit.
Getting a vast amount of songs with the Spotify API wasn’t as easy as expected. The only way to get several tracks is by specifying a track name, an artist, an album name, or a playlist name. To have the largest set of all-genres tracks, we decided to take the official playlists made by Spotify, going from Classic to Rock, and we extracted all the songs from these playlists. Finally, our data was composed of the features of approximately 2000 songs.

Second step — Training data
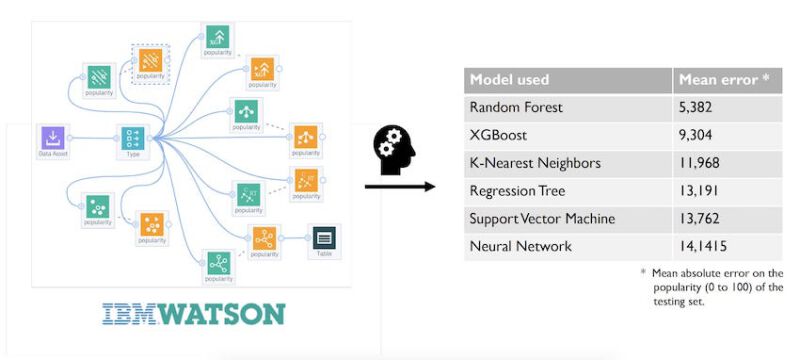
This hackathon aimed to use at best the given tools of the IBM Cloud. We mostly used the IBM Watson Studio that provides tools for data scientists to collaboratively and efficiently work with data to build and train models at scale. It gave us the possibility to quickly visualize and discover insights from our data.
We trained our data on multiple machine learning algorithms and kept the one that gave us the least mean absolute error (MAE). The Random Forest algorithm gave pretty good results with a MAE of approximately 5 (out of 100), and so it becomes the algorithm that we used for our model.
Third step — Predicting buzz
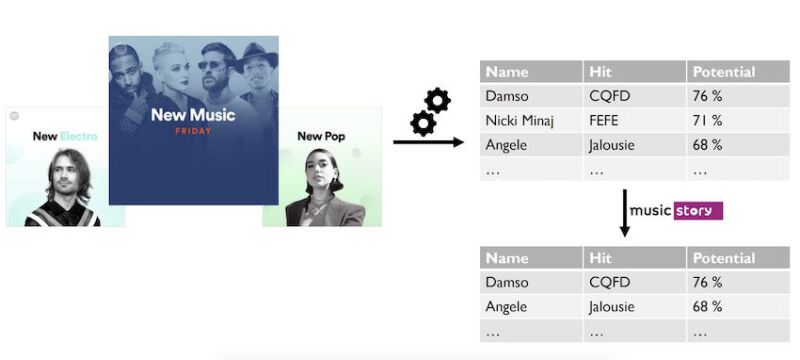
The last step of the process was to test our model on new tracks. The Spotify API allows us to get a list of new releases. These releases were passed as inputs in our algorithm to analyze their features and compute for each one of them a predicted popularity score. This predicted score corresponds to a percentage for a song to be a hit.
In the output list of potential hits, filtering must be done through the artists to keep the Belgian, Dutch, and French ones. Unfortunately, this filtering can’t be done with the Spotify API, as it does not provide any feature concerning an artist’s nationality. A solution to this problem consists of using another Web API, called “Music Story”, which allows collecting a set of data on more than 195 000 artists, including their nationality.
Notice that additional filtering is necessary from Sabam to get rid of the artists that have already been affiliated.
Final application
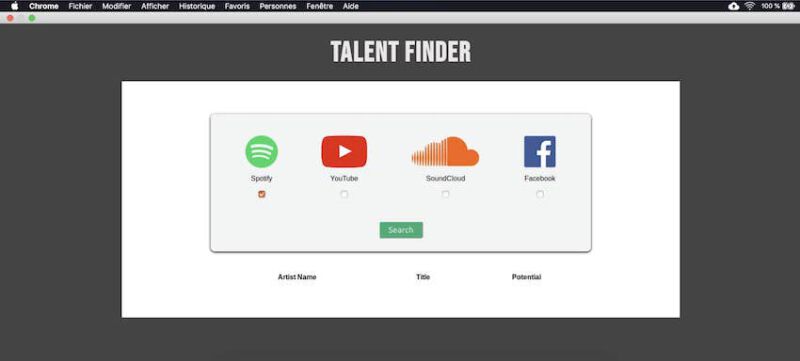
Finally, our solution to the Sabam problem is a web application with a user-friendly interface. The user only has to select the different platforms on which he/she wants to search for new talents — only Spotify is supported for the moment — and then clicks the search button. After less than a minute, a complete list of future buzz artists appears on his screen, letting the user choose to contact the ones he is interested in.