A brief history of NLP
Natural language processing (NLP) is a field at the intersection of linguistics and computer science concerned with developing techniques to process and analyze natural language data. The purpose of these techniques is to achieve human-like language processing for a range of tasks or applications.
Although it has gained enormous interest in recent years, research in NLP has been going on for several decades dating back to the late 1940s. This review divides its history into two main periods: NLP before and during the deep learning era.
NLP before the deep learning era

1950 - 1960. It is generally agreed that Weaver’s memorandum 1 brought the idea of the first computer-based application related to natural language: machine translation. It subsequently inspired many projects, notably the Georgetown experiment,2 a joint project between IBM and Georgetown University that successfully demonstrated the machine translation of more than 60 Russian sentences into English. The researchers accomplished this feat using hand-coded language rules, but the system failed to scale up to general translation. Early work in machine translation was simple: most systems used dictionary-lookup of appropriate words for translation and reordered the words after translation to fit the target language’s word-order rules. This produced poor results, as the lexical ambiguity inherent in natural language was not considered. The researchers then progressively realized that the task was a lot harder than anticipated, and they needed an adequate theory of language. It took until 1957 to introduce the idea of generative grammar,3 a rule-based system of syntactic structures that brought insight into how mainstream linguistics could help machine translation.
1960 - 1970. Due to the development of parsing algorithms and the syntactic theory of language, the 1950s were flooded with over-enthusiasm. People believed that fully automatic high-quality translation systems would produce results indistinguishable from those of human translators and that such systems would be in operation within a few years. Given the then-available linguistic knowledge and computer systems, this thought was completely unrealistic. After years of research and millions of dollars spent, machine translations were still more expensive than manual human translations, and there were no computers that came anywhere near being able to carry on a basic conversation. In 1966, the ALPAC released a report 4 that concluded that MT was not immediately achievable and recommended the research community to stop funding it. This had the effect of substantially slowing down machine translation research and most work in other NLP applications.
Despite this significant slowdown, some exciting developments were born during the years following the ALPAC report, both in theoretical issues and in constructing prototype systems. Theoretical work in the late 1960s and early 1970s mainly focused on how to represent meaning. Researchers developed new grammar theories that were computationally tractable for the first time, particularly after introducing transformational generative grammars,5 which were criticized for being too syntactically oriented and not lending themselves easily to computational implementation. As a result, many new theories appeared to explain syntactic anomalies and provide semantic representations, such as case grammar,6 semantic networks,7 augmented transition networks,8 and conceptual dependency theory.9 Alongside theoretical development, this period also saw the birth of many exciting prototype systems. ELIZA 10 was built to replicate the conversation between a psychologist and a patient by merely permuting or echoing the user input. SHRDLU 11 was a simulated robot that used natural language to query and manipulate objects inside a very simple virtual micro-world consisting of some color blocks and pyramids. LUNAR 12 was developed as an interface system to a database containing information about lunar rock samples using augmented transition networks. Lastly, PARRY 13 attempted to simulate a person with paranoid schizophrenia based on concepts, conceptualizations, and beliefs.
1970 - 1980. The 1970s brought new ideas into NLP, such as building conceptual ontologies which structured real-world information into computer-understandable data. Examples are MARGIE,14 TaleSpin,15 QUALM,16 SAM,17 PAM 18 and Politics.19
1980 - 1990. In the 1980s, many significant problems in NLP were addressed using symbolic approaches,20 21 22 23 24 i.e., complex hard-coded rules and grammars to parse language. Practically, the text was segmented into meaningless tokens (words and punctuation). Representations were then manually created by assigning meanings to these tokens and their mutual relationships through well-understood knowledge representation schemes and associated algorithms. Those representations were eventually used to perform deep analysis of linguistic phenomena.
1990 - 2000. Statistical models 25 26 27 28 came as a revolution in NLP in the late 1980s and early 1990s, replacing most natural language processing systems based on complex sets of hand-written rules. This progress resulted from both the steady increase of computational power and the shift to machine learning algorithms. While some of the earliest-used machine learning algorithms, such as decision trees,29 30 produced systems similar in performance to the old school hand-written rules, statistical models broke through the complexity barrier of hand-coded rules by creating them through automatic learning, which led researchers to focus on these models increasingly. At the time, these statistical models were capable of making soft, probabilistic decisions.
NLP during the deep learning era
From the 2000s, neural networks begin to be used for language modeling, aiming to predict the next term in a text given the previous words.
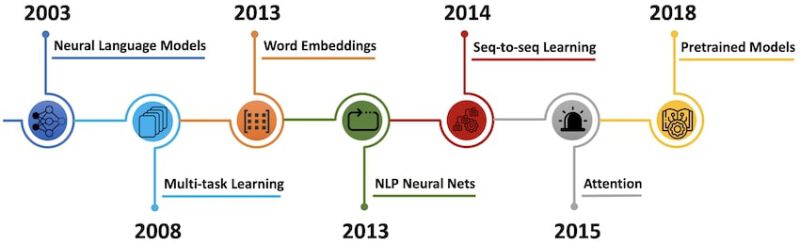
2003. Bengio and others proposed the first neural language model 31 that consists of a one-hidden layer feed-forward neural network. They also introduced what is now referred to as word embedding, a real-valued word feature vector in \(R^d\). More precisely, their model took input vector representations of the \(n\) previous words, which were looked up in a table learned together with the model. The vectors were fed into a hidden layer, whose output was then provided to a softmax layer that predicted the next word of the sequence. Although classic feed-forward neural networks have been progressively replaced with recurrent neural networks 32(RNNs) for language modeling,33 they remain in some settings competitive with recurrent architectures, the latter being impacted by “catastrophic forgetting”.34 Furthermore, the general building blocks of Bengio’s network are still found in most neural language and word embedding models nowadays.
2008. Collobert and Weston applied multi-task learning,35 a sub-field of machine learning in which multiple learning tasks are solved simultaneously to neural networks for NLP. They used a single convolutional neural network 36(CNN) that, given a sentence, could output many language processing predictions such as part-of-speech tags, named entity tags, and semantic roles. The entire network was trained jointly on all the tasks using weight-sharing of the look-up tables, which enabled the different models to collaborate and share general low-level information in the word embedding matrix. As models are increasingly evaluated on multiple tasks to gauge their generalization ability, multi-task learning has gained importance and is now used across a wide range of NLP tasks. Also, their paper turned out to be a discovery that went beyond multi-task learning. It spearheaded ideas such as pre-training word embeddings and using CNNs for texts that have only been widely adopted in the last years.
2013. Mikolov and others introduced arguably the most popular word embedding model: Word2Vec.37 38 Although dense vector representations of words have been used as early as 2003, the main innovation proposed in their paper was an efficient improvement of the training procedure by removing the hidden layer and approximating the loss function. Together with the efficient model implementation, these simple changes enabled large-scale training of word embeddings on vast corpora of unstructured text. Later that year, they improved the Word2Vec model by employing additional strategies to enhance training speed and accuracy. While these embeddings are not conceptually different from those learned with a feed-forward neural network, training on a vast corpus enables them to capture some relationships between words such as gender, verb tense, and country-capital relations, which initiated much interest in word embeddings as well as in the origin of these linear relationships.39 40 41 42 However, what made word embeddings a mainstay in current NLP was the evidence that using pre-trained embeddings as initialization improved performance across a wide range of downstream tasks. Despite many more recent developments, Word2Vec is still a popular choice and widely used today.
The year 2013 also marked the adoption of neural network models in NLP, in particular three well-defined types of neural networks: recurrent neural networks 32(RNNs), convolutional neural networks 36(CNNs), and recursive neural networks.43 Because of their architecture, RNNs became famous for dealing with the dynamic input sequences ubiquitous in NLP. However, Vanilla RNNs were quickly replaced with the classic long-short term memory networks 44(LSTMs), as they proved to be more resilient to the vanishing and exploding gradient problem. Simultaneously, convolutional neural networks, which were then beginning to be widely adopted by the computer vision community, started to apply to natural language.45 46 The advantage of using CNNs for dealing with text sequences is that they are more parallelizable than RNNs, as the state at every time step only depends on the local context (via the convolution operation) rather than all past states as in the RNNs. Finally, recursive neural networks were inspired by the principle that human language is inherently hierarchical: words are composed into higher-order sentences, which can themselves be recursively combined according to a set of production rules. Based on this linguistic perspective, recursive neural networks treated sentences as trees rather than as sequences. Some research also extended RNNs and LSTMs to work with hierarchical structures.47
2014. Sutskever and others proposed sequence-to-sequence learning,48 an end-to-end approach for mapping one sequence to another using a neural network. In their method, an encoder neural network processes a sentence term by term and compresses it into a fixed-size vector. Then, a decoder neural network predicts the output sequence symbol by symbol based on the encoder state and the previously predicted symbols taken as input at every step. Encoders and decoders for sequences are typically based on RNNs, but other architectures have also emerged. Recent models include deep-LSTMs,49 convolutional encoders,50 51 the Transformer,52 and a combination of an LSTM and a Transformer.53 Machine translation turned out to be the perfect application for sequence-to-sequence learning. The progress was so significant that Google announced in 2016 that it was officially replacing its monolithic phrase-based machine translation models in Google Translate with a neural sequence-to-sequence model.
2015. Bahdanau and others introduced the principle of attention,54 one of the core innovations in neural machine translation (NMT) that enabled NMT models to outperform classic sentence-based MT systems. It alleviates the main bottleneck of sequence-to-sequence learning, which is its requirement to compress the entire content of the source sequence into a vector representation. Indeed, attention allows the decoder to look back at the source sequence hidden states, which are then combined through a weighted average and provided as an additional input to the decoder. Attention is potentially useful for any task that requires making decisions based on certain parts of the input. For now, it has been applied to constituency parsing,55 reading comprehension,56, and one-shot learning.57 More recently, a new form of attention has appeared, called self-attention, being at the core of the Transformer architecture. In short, it is used to look at the surrounding words in a sentence or paragraph to obtain more contextually sensitive word representations.
2018. The latest major innovation in the world of NLP is undoubtedly large pre-trained language models. While first proposed in 2015,58 only recently were they shown to give a considerable improvement over the state-of-the-art methods across a diverse range of tasks. Pre-trained language model embeddings can be used as features in a target model,59 or a pre-trained language model can be fine-tuned on target task data,60 61 62 63 which have shown to enable efficient learning with significantly fewer data. The main advantage of these pre-trained language models comes from their ability to learn word representations from large unannotated text corpora, which is particularly beneficial for low-resource languages where labeled data is scarce.
References
-
Shannon and Weaver. The mathematical theory of information. Urbana: University of Illinois Press, 1949. ↩
-
Dostert. The georgetown-ibm experiment. Machine translation of languages, pages 124–135, 1955. ↩
-
Chomsky. Syntactic structures. The Hague: Mouton, 1957. ↩
-
Pierce et al. Language and machines — computers in translation and linguistics. ALPAC report, National Academy of Sciences, 1966. ↩
-
Chomsky. Aspects of the theory of syntax. Cambridge: M.I.T. Press, 1965. ↩
-
Fillmore. The case for case. Bach and Harms (Ed.): Universals in Linguistic Theory, 1968. ↩
-
Collins et al. Retrieval time from semantic memory. Journal of Verbal Learning and Verbal Behavior, 8(2):240 – 247, 1969. ↩
-
Woods. Transition network grammars for natural language analysis. Communications of the ACM, 13(10):591–606, 1970. ↩
-
Schank. Conceptual dependency: A theory of natural language understanding. Cognitive psychology, 3(4):552–631, 1972. ↩
-
Weizenbaum. Eliza—a computer program for the study of natural language communication between man and machine. Communications of the ACM, 9(1):36–45, 1966. ↩
-
Winograd. Procedures as a representation for data in a computer program for understanding natural language. Technical report, Massachusetts Institute of Technology, Cambridge Project, 1971. ↩
-
W Woods et al. The lunar sciences natural language information system: Final report. Woods discusses the LUNAR program which answers scientist’s questions about the moon rocks, 1972. ↩
-
Colby. Ten criticisms of parry. ACM SIGART Bulletin, 48:5–9, 1974. ↩
-
Schank and Abelson. Scripts, plans, and knowledge. In IJCAI, 75:51–157, 1975. ↩
-
Meehan. The metanovel: writing stories by computer. Technical report, Yale Univ. New Haven. Conn. Dept. of Computer Science, 1976. ↩
-
Lehnert. A conceptual theory of question answering. In Proceedings of the 5th international joint conference on Artificial intelligence, 1:158–164, 1977. ↩
-
Cullingford. Script application: computer understanding of newspaper stories. Technical report, Yale Univ. New Haven. Conn. Dept. of Computer Science, 1978. ↩
-
Schank and Wilensky. A goal-directed production system for story understanding. In Pattern-directed inference systems, pages 415–430, 1978. ↩
-
Carbonell. Subjective understanding: computer models of belief systems. Technical report, Yale Univ. New Haven. Conn. Dept. of Computer Science, 1979. ↩
-
Charniak. Passing markers: A theory of contextual influence in language comprehension. Cognitive science, 7(3):171–190, 1983. ↩
-
Dyer. The role of affect in narratives. Cognitive Science, 7(3):211–242, 1983. ↩
-
Riesbeck and Martin. Direct memory access parsing. Experience, memory and reasoning, pages 209–226, 1986. ↩
-
Grosz et al. Team: an experiment in the design of transportable natural-language interfaces. Artificial Intelligence, 32(2):173–243, 1987. ↩
-
Hirst. Semantic interpretation and ambiguity. Artificial Intelligence, 34(2):131 – 177, 1987. ISSN 0004-3702. ↩
-
Bahl et al. A tree-based statistical language model for natural language speech recognition. IEEE Transactions on Acoustics, Speech, and Signal Processing, 37(7):1001–1008, 1989. ↩
-
Brill et al. Deducing linguistic structure from the statistics of large corpora. In Proceedings of the 5th Jerusalem Conference on Information Technology, pages 380–389, 1990. ↩
-
Chitrao and Grishman. Statistical parsing of messages. In Speech and Natural Language: Proceedings of a Workshop Held at Hidden Valley, Pennsylvania, 1990. ↩
-
Brown et al. A statistical approach to machine translation. Computational linguistics, 16(2):79–85, 1991. ↩
-
Tanaka. Verbal case frame acquisition from a bilingual corpus: Gradual knowledge acquisition. In Proceedings of the 15th International Conference on Computational Linguistics, 2:727–731, 1994. ↩
-
Allmuallim et al. Two methods for learning translation rules from examples and a semantic hierarchy. In Proceedings of the 15th International Conference on Computational Linguistics, 1994. ↩
-
Bengio et al. A neural probabilistic language model. Journal of machine learning research, 3(Feb):1137–1155, 2003. ↩
-
Elman. Finding structure in time. Cognitive science, 14(2):179–211, 1990. ↩ ↩2
-
Mikolov et al. Recurrent neural network based language model. In Eleventh annual conference of the international speech communication association, 2010. ↩
-
Daniluk et al. Frustratingly short attention spans in neural language modeling. arXiv preprint arXiv:1702.04521, 2017. ↩
-
Collobert and Weston. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th international conference on Machine learning, pages 160–167, 2008. ↩
-
LeCun et al. Object recognition with gradient-based learning. In Shape, contour and grouping in computer vision, pages 319–345, 1999. ↩ ↩2
-
Mikolov et al. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781, 2013. ↩
-
Mikolov et al. Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems, pages 3111–3119, 2013. ↩
-
Mimno and Thompson. The strange geometry of skip-gram with negative sampling. In Empirical Methods in Natural Language Processing, 2017. ↩
-
Arora et al. Linear algebraic structure of word senses, with applications to polysemy. Transactions of the Association for Computational Linguistics, 6:483–495, 2018. ↩
-
Antoniak and Mimno. Evaluating the stability of embedding-based word similarities. Transactions of the Association for Computational Linguistics, 6:107–119, 2018. ↩
-
Wendlandt et al. Factors influencing the surprising instability of word embeddings. arXiv preprint arXiv:1804.09692, 2018. ↩
-
Socher et al. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 conference on empirical methods in natural language processing, pages 1631–1642, 2013. ↩
-
Hochreiter an Schmidhuber. Long short-term memory. Neural computation, 9(8): 1735–1780, 1997. ↩
-
Kalchbrenner et al. A convolutional neural network for modelling sentences. arXiv preprint arXiv:1404.2188, 2014. ↩
-
Kim. Convolutional neural networks for sentence classification. arXiv preprint arXiv:1408.5882, 2014. ↩
-
Tai et al. Improved semantic representations from tree-structured long short-term memory networks. arXiv preprint arXiv:1503.00075, 2015. ↩
-
Sutskever et al. Sequence to sequence learning with neural networks. In Advances in neural information processing systems, pages 3104–3112, 2014. ↩
-
Wu et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv preprint arXiv:1609.08144, 2016. ↩
-
Kalchbrenner et al. Neural machine translation in linear time. arXiv preprint arXiv:1610.10099, 2016. ↩
-
Gehring et al. Convolutional sequence to sequence learning. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pages 1243–1252, 2017. ↩
-
Vaswani et al. Attention is all you need. In Advances in neural information processing systems, pages 5998–6008, 2017. ↩
-
Chen et al. The best of both worlds: Combining recent advances in neural machine translation. arXiv preprint arXiv:1804.09849, 2018. ↩
-
Bahdanau et al. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473, 2014. ↩
-
Vinyals et al. Pointer networks. In Advances in neural information processing systems, pages 2692–2700, 2015. ↩
-
Hermann et al. Teaching machines to read and comprehend. In Advances in neural information processing systems, pages 1693–1701, 2015. ↩
-
Vinyals et al. Matching networks for one shot learning. In Advances in neural information processing systems, pages 3630–3638, 2016. ↩
-
Dai and Le. Semi-supervised sequence learning. In Advances in neural information processing systems, pages 3079–3087, 2015. ↩
-
Peters et al. Deep contextualized word representations. arXiv preprint arXiv:1802.05365, 2018. ↩
-
Devlin et al. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018. ↩
-
Howard and Ruder. Universal language model fine-tuning for text classification. arXiv preprint arXiv:1801.06146, 2018. ↩
-
Radford et al. Language models are unsupervised multitask learners. OpenAI Blog, 1(8):9, 2019. ↩
-
Yang et al. Xlnet: Generalized autoregressive pretraining for language understanding. In Advances in neural information processing systems, pages 5754–5764, 2019. ↩